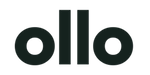


Most advice about Interactive Response Technology is dangerously incomplete.
The glossy version says IRT automates randomisation, drug assignment, and supply. That part is true. The dangerous omission is this: your IRT platform only performs as well as the infrastructure, identity model, document controls, and integration layer underneath it. If those foundations are weak, the software doesn't save you. It amplifies the failure.
That matters because IRT already operates at industrial scale. Industry data cited by Lifebit describes over 35 million patient transactions across more than 102,000 sites worldwide. That isn't abstract platform marketing. It's a reminder that when you rely on interactive response technology, you're putting a regulated operational dependency on top of systems that can still fail in very ordinary ways such as throttling, broken inheritance, and poor data governance.
Your IRT Vendor Is Not Your Saviour
Your vendor sells an application. Your risk sits in the estate around it.
That's the mistake I see repeatedly. An IT team buys an IRT platform, listens to the implementation partner talk about workflows, and assumes the hard part lives inside the product. It doesn't. The hard part lives in identity boundaries, document structures, retention, permissions, and the ugly integration behaviours no sales engineer wants to discuss.
The scale alone should make you cautious. Lifebit's industry data describes over 35 million patient transactions across more than 102,000 sites worldwide in IRT operations, which shows just how operationally critical these systems have become in practice (Lifebit industry scale reference). At that scale, one weak dependency can stop enrolment, delay allocation, or scramble traceability.
The real dependency nobody wants to own
Your IRT vendor doesn't own your SharePoint sprawl. They don't own your Entra ID design. They don't own the inherited permissions that nobody cleaned up after the last tenant restructuring. They certainly don't own the migration shortcuts your team took two years ago that left duplicate records, stale integrations, and inconsistent metadata across regulated libraries.
Your trial operations team experiences the outage. Your compliance team inherits the problem. Your vendor points at the contract boundary.
If you need a simple analogy, look at how teams evaluate documentation platforms. A decent best knowledge base software comparison helps buyers think beyond front-end features and look at structure, governance, and maintainability. IRT needs the same discipline, except the cost of getting it wrong is far higher.
The documentation says automated. Reality says fragile.
Documentation usually presents IRT as a neat sequence. Enrol patient. Randomise. Assign drug. Trigger supply. Log activity. In reality, every one of those steps depends on data moving across systems that weren't designed together and are often sitting on Microsoft 365 estates with years of compromise baked in.
We often see clients fail when they treat IRT as an application rollout instead of an enterprise control-plane dependency. That's why procurement discipline matters long before implementation starts. If your team hasn't tightened requirements around governance, integration ownership, and operational evidence, start there with a proper request for proposal process.
What IRT Is When an Architect Is Asking
An architect shouldn't define Interactive Response Technology by the screen a site coordinator sees.
Define it by control, data flow, and failure domain.
According to Adragos Pharma, Interactive Response Technology in clinical trials is the operational control plane for randomisation, drug assignment, and trial supply management, with real-time data coordination across sites, depots, and sponsors (Adragos overview of IRT operations). That's the useful definition because it forces you to ask the right questions. What rules engine makes the decision? What system persists the audit trail? What identity governs each transaction? Where does the evidence live when an auditor asks for it?
Three parts matter more than the interface
Most enterprise teams should think about IRT in three layers:
- Rules execution layer. In this layer, randomisation, treatment allocation, and supply logic run. If your mappings, identities, or upstream triggers are wrong, the system makes the wrong decision very efficiently.
- Operational logistics layer. It coordinates site demand, depot activity, and shipment signals. Timing issues here become business issues.
- Audit and evidence layer. Many teams under-design this layer. If the action happened but you can't prove who triggered it, what data informed it, and which controlled record was current, you've created a compliance problem.
Architects need to model flows, not screens
The user story says, “site enters patient data”. The architectural story says something else.
A person authenticates through a governed identity boundary. Data enters a controlled workflow. Integration sends and receives records from adjacent platforms. Logs capture state changes. Retention policies preserve evidence. Access controls prevent privilege creep. Every one of those points can break.
That's why governance work can't sit off to the side as a later workstream. If your team still treats Power Platform and Microsoft 365 controls as “admin tidy-up”, you're already behind. Tighten that foundation first with a proper Power Platform governance model.
Architect's rule: If you can't draw the system-of-record boundaries, the trust boundaries, and the evidence boundaries for your IRT estate, you don't understand the risk yet.
What the architect should secure first
A practical review should include:
| Focus area | What to inspect |
|---|---|
| Identity | Service principals, role mapping, conditional access, least-privilege design |
| Data flow | Which systems send patient, allocation, and supply events |
| Evidence | Where logs, manifests, approvals, and exceptions are retained |
| Governance | How records are classified, retained, and protected from ad hoc change |
IRT is not “clinical software” in isolation. It is a regulated decision engine sitting on top of enterprise plumbing. Treat it that way.
A Typical IRT Workflow and Its Inevitable Breaking Points
The textbook workflow looks clean. The actual one usually isn't.
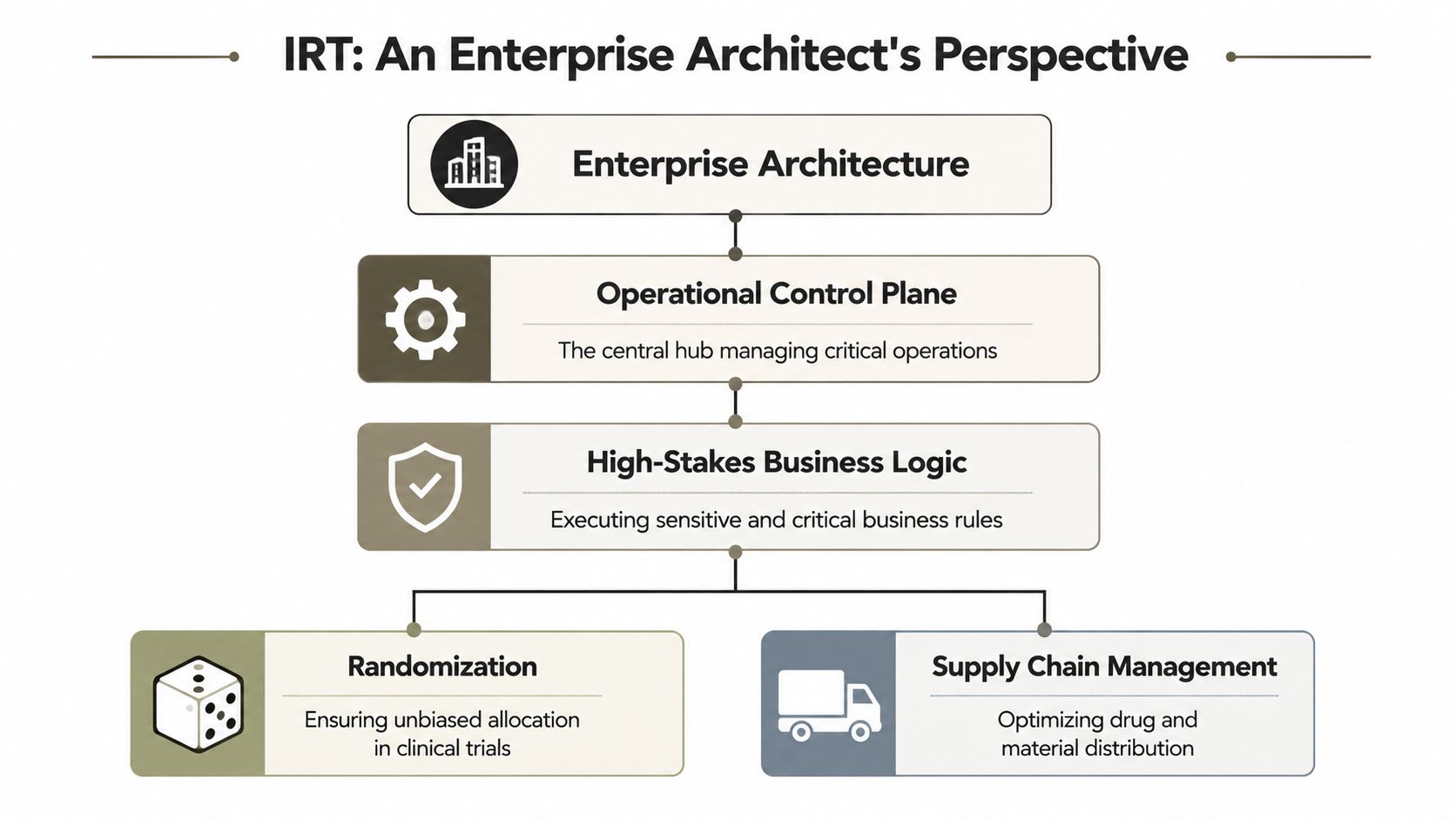
Start with enrolment. A site enters subject details. The IRT validates eligibility and prepares the randomisation event. On a slide, that step takes a box and an arrow. In production, it relies on identity tokens, field mappings, upstream data quality, and back-end repositories staying in sync.
We often see clients fail when they assume “it connected once” means “it is operationally stable”. It isn't. Stable demos are not the same as resilient operations.
Step one enrolment fails earlier than teams expect
A common failure starts before randomisation. Records arrive from a migrated environment carrying stale identifiers or conflicting references. A GUID conflict from poor tenant hygiene doesn't look dramatic in a workshop. In production, it can stop matching logic or write duplicate records into downstream stores.
Then the workaround begins. Someone exports data. Someone else updates values manually. The trial keeps moving, but your evidence chain just weakened.
Step two randomisation depends on more than the algorithm
Randomisation engines get the attention because they're mission critical. The integration fabric around them gets neglected because it looks mundane.
That's a serious mistake. Official Microsoft Learn documentation confirms technical constraints such as API throttling, list view threshold behaviour around the 5k limit, path limitations, and permission complexity in Microsoft 365 and SharePoint. The documentation says the platform supports enterprise-scale processing. Reality says throughput, payload shape, retry logic, and object structure decide whether your workflow survives load.
A delayed API call isn't an IT nuisance when it holds up treatment allocation. It's an operational deviation waiting for a root-cause report.
To see how brittle approval and orchestration logic becomes once real dependencies enter the picture, look at a typical Power Automate approval workflow pattern. The mechanics are useful. The hidden failure modes are where experienced architects earn their keep.
A quick visual helps expose where the “simple” workflow fractures:
Step three supply requests break on boring infrastructure
The next stage should trigger supply activity. The IRT sends the event. Documents should update. Shipping instructions should flow. Manifests should remain traceable.
Old SharePoint estates sabotage regulated operations. Long file paths, ugly folder nesting, broken inheritance, and badly governed libraries turn “automated handoff” into “manual chase”. Microsoft Learn documents these constraints clearly. Teams still ignore them because they don't fail during design workshops. They fail under pressure, during real operational peaks, when nobody has time to untangle them.
The workflow isn't broken where you're looking
Here's the pattern:
- Business users blame the IRT because that's the visible system.
- Vendors blame the customer environment because that's where the dependency failed.
- Internal IT blames integration complexity because no single team owned the whole path.
All three are partly right. None of that helps you during an audit.
The safe assumption is simple. Every “automated” IRT step will eventually hit a non-obvious dependency. If your estate hasn't been engineered for those breakpoints, the workflow hasn't been engineered at all.
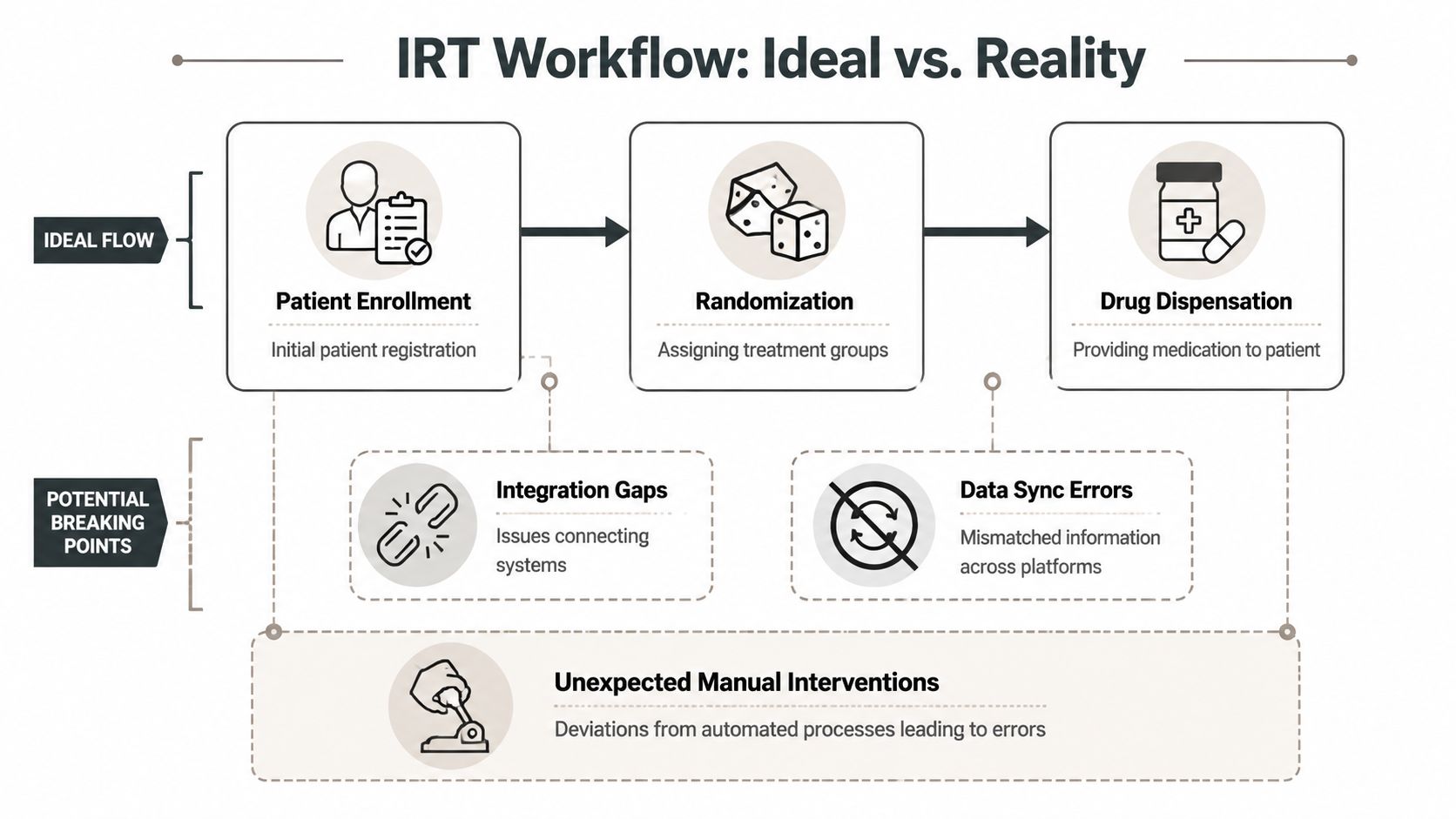
The Technical and Compliance Risks Your Vendor Won't Mention
Sales teams like talking about randomisation logic and user adoption. They avoid the plumbing because the plumbing kills projects.
The biggest risk is integration fragility. Independent research from ISR Reports found that 61% of respondents selected integration with EDC, ePRO, CTMS, and other data systems as one of their Top 5 criteria for choosing an IRT provider (ISR Reports on IRT selection criteria). That's the clearest signal you'll get. Buyers know the main danger sits in the joins between systems.
Integration fragility is the first real threat
Vendors often present integration as a checklist item. Connect to EDC. Connect to ePRO. Connect to CTMS. Job done.
Reality is rougher. Integration means schema alignment, error handling, retries, sequencing, identity trust, and operational ownership. If one side changes a field expectation or pushes data in the wrong order, your workflow may still run while your records stop agreeing with each other. That's worse than an obvious outage because the discrepancy can sit undetected.
A threat and risk assessment discipline helps here. If your organisation needs a good external example of how to frame that work, Accelerate IT Services Inc. outlines the mindset well. You need the same seriousness for IRT-connected systems.
SharePoint limits become audit problems
I've seen teams dismiss the 5k list view threshold as an admin annoyance. In regulated operations, that attitude is reckless.
Official Microsoft Learn documentation confirms these platform constraints. If your evidence store, exception log, or manifest history depends on list structures that users can't query reliably at scale, you haven't just created a usability problem. You've weakened your ability to retrieve controlled records under inspection conditions.
The same goes for broken inheritance. That isn't harmless clutter. It's uncontrolled access drift. In a GxP-adjacent or heavily regulated workflow, uncontrolled access is a governance failure with technical symptoms.
Hard truth: your audit trail isn't credible if nobody can prove the permissions model stayed controlled over time.
EU governance raises the stakes in Ireland
For Ireland and the wider EU, this gets stricter. EU clinical-trial operations are governed by CTR and CTIS, pushing teams towards auditable, centralised trial records and controlled workflow traceability. That means your implementation has to support inspection-ready logs, role-based access, and timely status reporting in practice, not just in policy.
If your data sits across half-governed SharePoint sites, legacy Teams workspaces, and service accounts nobody trusts, your issue isn't software capability. It's governance drift.
That's where defensive controls matter. Proper data loss prevention controls won't fix a bad architecture, but they do expose and reduce some of the leakage paths teams otherwise miss.
Four risks worth naming directly
- Integration drift. The systems remain “connected” while records diverge unnoticed.
- Validation gaps. Teams trust the transaction because it processed, not because the underlying state remained consistent.
- Compliance exposure. Access, retention, and traceability controls degrade faster than project teams admit.
- Scalability failure. Throughput constraints appear only when real load arrives, usually during the least convenient trial window.
If your vendor isn't walking you through those risks in technical detail, they're discussing adoption. You should be discussing liability.
The False Economy of DIY Implementation
DIY IRT implementation looks cheaper only on the day finance reviews the proposal.
A vendor licence plus internal effort seems sensible. Your admins know Microsoft 365. Your architects know integration patterns. Your business analysts know the trial process. On paper, that feels good enough.
It usually isn't.
The hidden bill arrives later
DIY teams rarely budget for the right things. They budget for implementation tasks. They don't budget for debugging edge cases in identity federation, cleaning up malformed document structures, remediating permission sprawl, or rebuilding migration damage from earlier projects.
The documentation says tools such as SPMT and ShareGate can move content. That's true, within bounds. Reality is harsher in enterprise estates. SPMT is fine for small, contained transfers. ShareGate is useful and far better, but even it hits ugly edges when you inherit broken metadata, long path mess, customisations, or years of inconsistent governance. Microsoft Learn confirms the platform constraints. The tooling can't wish them away.
Complexity has increased, not decreased
Recent industry coverage notes that the rise of decentralised and hybrid trials in the last 12 months is increasing complexity. IRT now needs to work with eConsent, home-health workflows, and external logistics, which increases the chance of reconciliation gaps, API throttling, and randomisation failures for unprepared teams (Clinical Supply Consulting on recent IRT trends).
That point matters because internal teams often build for the current workflow while the operating model is already shifting underneath them.
A DIY implementation tends to fail in one of three ways:
- The team underestimates the estate. Nobody fully maps the dependency chain.
- The team overestimates the tools. Migration and admin tools get treated as architecture.
- The team inherits support debt. The go-live succeeds narrowly, then ops spends months firefighting exceptions.
Specialist work is risk transfer, not “extra cost”
Finance often gets the decision wrong. They compare line items, not exposure.
The specialist fee isn't payment for clicking through setup screens. It's payment for knowing where the system breaks before it breaks. It's payment for scripts, testing discipline, governance patterns, rollback planning, and scar tissue from previous failures.
A useful way to frame this internally is the same distinction explored in Microsoft 365 admin vs consultant. Admin capability keeps the estate running. Specialist capability protects you during high-risk change.
Practical rule: If failure affects regulated records, supply coordination, or inspection evidence, DIY is not prudent engineering. It's unmanaged risk with a friendlier label.
The Ollo Verdict Your Action Plan for IRT Success
Your IRT project will not succeed because the demo looked polished.
It will succeed only if your underlying Microsoft 365, SharePoint, identity, and governance estate can support controlled transactions, reliable integrations, and inspection-ready evidence under pressure. That's the part teams keep underfunding.
EU clinical-trial operations are governed by CTR and CTIS, which require auditable, centralised records and controlled workflow traceability. In Ireland, that means your IRT implementation must support inspection-ready logs in practice, not just in design documents (Salesforce overview of IRT and EU trial operations).
Use this readiness check honestly
If your team can't answer yes to these questions, your risk is already live.
- Identity control. Have you locked down service accounts, app registrations, and role mappings with least-privilege and Zero Trust thinking?
- Evidence design. Can you show where every critical IRT-triggered action is logged, retained, and retrievable for inspection?
- SharePoint fitness. Have you checked for long path problems, broken inheritance, poor metadata, and list structures that won't hold up under operational load?
- Integration resilience. Have you tested retries, sequencing, exception handling, and throughput under realistic transaction patterns?
- Change discipline. Do you know who owns schema changes, connector updates, and permission reviews after go-live?
- Recovery path. If a sync fails or a supply event misfires, do you have a documented and tested operational fallback?
My blunt recommendation
Use SPMT for very small, low-risk moves. Use ShareGate for controlled mid-market migration work where the estate is already clean. For anything tied to regulated IRT operations, cross-tenant complexity, or evidence-critical SharePoint restructuring, you need custom scripting, architecture discipline, and deep remediation experience.
That's the verdict. Not because the tools are bad. Because the failure modes sit outside the tool brochure.
Your team doesn't need another optimistic implementation plan. It needs a hostile review of every dependency that can corrupt traceability, slow allocation, or expose controlled records. If nobody is doing that work, nobody is protecting the project.
If your organisation is preparing for high-stakes Microsoft 365, SharePoint, or identity change around regulated workloads, talk to Ollo. We handle the ugly parts most providers avoid, including tenant-to-tenant consolidation, Entra ID redesign, and rescue work when governance debt starts threatening live operations.



