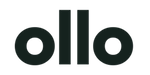


Most advice about a money transfer application is wrong at the architectural level. It treats the product as a mobile interface with a payments connector behind it. That's how teams end up shipping a polished front end on top of weak controls, opaque routing, and brittle settlement logic.
If you're a CTO or IT Director, stop calling this a feature build. You're being asked to stand up financial infrastructure. That means liability, auditability, fraud exposure, and operational failure modes that won't show up in a demo.
Your Next Project or Your Next Failure
A money transfer application doesn't fail because the button design was poor. It fails because the organisation underestimated what happens after the user presses Send.
The market pressure is obvious. Global remittance flows to low and middle income countries reached about $685 billion in 2024, while the average cost of sending money still sits around 6% according to Digipay Guru's remittance market summary. That combination tells you two things. First, the volume is enormous. Second, users still feel fee pain badly enough to switch providers when cost, speed, or trust breaks down.
That creates a brutal environment for any team trying to build or integrate a transfer platform. If your product can't reduce friction, explain cost clearly, and survive fraud events, users won't wait around while you fix the architecture in production.
What teams get wrong first
We often see clients fail when they assume the core problem is orchestration. It isn't. The harder problem is control.
A real money transfer application has to answer questions like these before anyone should approve a budget:
- Who owns compliance logic: Is it buried in app code, scattered across vendor rules, or enforced centrally?
- Who proves transaction history: Can your team reconstruct a transfer end to end without pulling logs from six systems?
- Who handles disputed authorisation: If a user was tricked into sending funds, what is your operational response?
- Who owns routing economics: Can you explain why one corridor costs more than another, and can your system adapt?
If you can't answer those questions, you're not building a product. You're assembling failure conditions.
Practical rule: If your programme plan treats compliance, fraud operations, and payout exceptions as phase-two work, the project is already off course.
The business risk hiding behind technical optimism
The documentation from platform vendors usually suggests that money movement is a sequence of API calls. Reality is harsher. Every cross-border flow carries identity risk, sanctions screening risk, reconciliation risk, FX exposure, and settlement uncertainty.
That matters in Ireland as much as anywhere else. Irish buyers don't operate in a protected niche. They operate in a market where digital transfer options compete on cost, speed, and trust. A delayed transfer doesn't just generate a support ticket. It creates refund pressure, complaint handling, operational investigation, and reputational damage.
A failed migration can embarrass an IT department. A failed transfer platform can create regulatory attention.
The Three-Tier Architecture That Will Define Your Success
Before your team argues about React, Flutter, .NET, or Node, settle the only issue that matters. Which layer carries which risk.

Digital transfer products have a structural cost advantage over traditional methods only when they are built and routed correctly, as reflected in Statistics Canada's comparative review of international money transfer methods. That sounds commercial, but it's really an architecture warning. Routing logic, fee logic, and payout path design sit in the system. If you get them wrong, your cost model collapses.
Presentation tier is your attack surface
The front end does more than collect form fields. It exposes your assumptions to users, fraudsters, and support teams.
If the app can't explain fees, expected delivery, identity checks, and payout constraints clearly, you create avoidable disputes. If it stores too much state on the client or trusts the device too much, you create abuse paths. If it masks operational uncertainty with optimistic status messages, you train users to distrust the platform.
That same lesson appears in adjacent regulated platforms. Teams evaluating a DEX development company UK provider often discover the same truth. The interface looks like the visible product, but the hidden transaction controls decide whether the service survives production.
Application tier is where projects usually break
This middle layer carries the business rules that executives wrongly call implementation detail. It should own:
- Identity orchestration: KYC, step-up authentication, device checks, and sanctions decisioning
- Transfer economics: fee calculation, FX quote handling, corridor constraints, and expiry logic
- Vendor abstraction: normalising inconsistent responses from payment, verification, and payout providers
- Exception handling: retries, dead-letter flows, manual review queues, and reversal states
Many teams under-design this layer. They wire vendor APIs directly into workflows and call it agility. It isn't. It's dependency sprawl.
If your organisation has already learned hard lessons in regulated cloud programmes, the same governance discipline described in Ollo's guidance on on-premise to cloud migration applies here. Keep control points explicit. Don't let expedient integration become permanent architecture.
Data tier is where trust lives or dies
Your back end isn't just a database. It is the evidential record.
A weak data tier creates three immediate problems:
| Risk area | What weak design looks like | Business consequence |
|---|---|---|
| Ledger integrity | Mutable transaction states with poor version history | You can't defend disputes or audits |
| Reconciliation | Separate truth sets across providers and internal systems | Finance and ops waste time proving what happened |
| Sensitive data handling | Overexposed personal and payment data | You increase regulatory and breach exposure |
The documentation says persistence is a storage concern. In reality, your ledger design decides whether anyone believes your transaction history.
The Ollo Verdict: keep the presentation tier thin, make the application tier authoritative, and design the data tier as an auditable record from day one. If your developers want to collapse those responsibilities for speed, stop them.
Tracing a Transaction Through the Gauntlet
Let's follow one transfer. Not the tidy version from a sales deck. The actual one.
A user opens your money transfer application and enters a recipient, amount, and corridor. From that moment, your system starts making promises. It's often overlooked how many of those promises depend on systems they don't fully control.
The transfer starts before funds move
The first checkpoint isn't payment. It's trust.
Your onboarding flow has to validate identity, assess risk, and decide whether the transfer should proceed, pause, or escalate. If you delay those checks until after payment intent is created, you create a queue of contaminated transactions that operations has to clean up manually.
Then comes quote construction, a stage where many apps unintentionally mislead users. The true total cost of a cross-border transfer isn't just the transfer fee. It also includes exchange-rate markup, intermediary fees, and payout method constraints on a specific Ireland-linked corridor, as noted in NerdWallet's overview of transfer cost factors. If your system can't answer the user's real question, which is "what final amount will arrive", then your quote engine is incomplete.
For teams dealing with document-heavy workflows and regulated approvals, the control patterns used in digital transaction management programmes are useful here too. Every handoff needs traceability. Every decision needs context.
The middle of the flow is where ambiguity multiplies
Now the user confirms. Your system authorises the sender, checks available funds or incoming payment status, and writes an internal transaction state.
Hidden complexity starts stacking up:
- FX timing: When was the rate locked, and for how long?
- Rail selection: Did your engine choose the cheapest route, the fastest route, or the only route available?
- Intermediary dependencies: Are there extra institutions in the chain that can delay or deduct?
- Payout mode constraints: Can the recipient receive via bank, card, wallet, or cash in that corridor?
Each answer affects support, reconciliation, and complaints later. If your team can't surface those decisions, operations will end up reading provider logs by hand.
Settlement is not the finish line
Most failed designs treat settlement as success. It isn't. Users care about receipt, availability, and proof.
Your system still has to confirm that the beneficiary received funds, that the status message is accurate, and that the final receipt matches what your quote engine implied at the start. If it doesn't, your support team becomes an investigative unit.
A transfer is only complete when your system can prove who initiated it, what was promised, how it was routed, what arrived, and why any difference occurred.
That proof has to survive complaints, reversals, and audit review. If it doesn't, the "happy path" in your architecture diagram was fiction.
The Non-Negotiable World of Security and Compliance
Teams love to say they'll harden the platform later. That's how they end up rewriting core flows under pressure from compliance, legal, and support after launch.

In a money transfer application, security and compliance aren't wrappers around the product. They shape authentication, data retention, approval design, transaction controls, incident response, and customer communication. If you bolt them on later, you don't get a tougher system. You get a slower and more confusing one.
Compliance logic belongs in the design, not the backlog
Your architects need to design around PSD2, GDPR, AML controls, and fraud handling from the start. That means the system must know when to challenge, when to block, when to record additional evidence, and when to hand a case to operations.
We often see technical teams hide these controls inside vendor products because it feels faster. That's a mistake. You still own the business risk when the rule set misfires, the evidence trail is incomplete, or the customer outcome becomes indefensible.
A useful external reference for security planning is this breakdown of PCI compliance requirements 2026. Not because it solves your transfer architecture, but because it reinforces the core lesson. Compliance isn't a policy memo. It's an engineering constraint.
If you're operating in a regulated Microsoft estate, the same governance mindset described in Microsoft 365 financial services compliance controls should already be familiar. Explicit control beats implied control every time.
APP fraud is the blind spot that keeps hurting firms
Authorised push payment fraud is a material threat and public content in Ireland still under-explains what happens when a user is tricked into sending money, as discussed in Zymr's analysis of money transfer app development risks, making simplistic product thinking dangerous.
A user doesn't care that the transfer was technically authorised. They care whether they were deceived, whether the funds can be stopped, what evidence they must provide, and who is liable. If your platform doesn't support those answers operationally, your incident response will collapse into guesswork.
That requires more than generic fraud scoring. You need:
- Behavioural controls: abnormal recipient patterns, device changes, unusual urgency signals, and payment context mismatches
- Customer challenge design: intervention messages that interrupt scam behaviour instead of becoming background noise
- Case management: evidence capture, timeline reconstruction, and escalation paths that support a defensible outcome
- Liability clarity: documented rules for reimbursement assessment, reversals, and customer communications
Here's a useful explainer on the threat environment before we go further:
Security failure becomes operational failure very quickly
A weak control model doesn't just increase fraud exposure. It also breaks support, complaints, and audit readiness.
Consider the difference:
| Control area | Weak implementation | Strong implementation |
|---|---|---|
| Authentication | Login-centric checks only | Transaction-aware authentication and step-up logic |
| Fraud monitoring | Static rules with poor context | Layered signals tied to transfer behaviour |
| Evidence retention | Fragmented logs across systems | Searchable event history attached to transaction records |
| Customer communications | Generic statuses and warnings | Clear, timed, case-relevant notices |
Field lesson: if your fraud tooling can't explain a decision to operations, legal, and the customer, it isn't mature enough.
The Ollo Verdict: if compliance is a fraction of the architecture effort, the programme is upside down. Build for challenge, evidence, and dispute from day one or don't launch.
The Integration Myth Why APIs Are Not a Silver Bullet
Your developers will hear the same pitch from every vendor. Use our API, outsource the hard parts, go live faster.
That story falls apart in production.
An international money transfer API can be a valid building block, but it doesn't remove architectural accountability. It shifts complexity into orchestration, monitoring, dependency management, and vendor escalation. This realization often occurs only after the first outage, the first unexplained failure state, or the first corridor-specific exception that the API docs barely mention.
Why plug and play rarely survives contact with reality
The documentation says POST a payload and receive a status. Reality is vendor throttling, asynchronous callbacks that arrive late or out of order, and error objects that don't tell your support team anything useful.
The worst pattern is multi-vendor chaining. One service handles identity. Another handles FX. Another handles disbursement. A fourth handles fraud review. At that point, your platform is no longer one system. It's a coordination problem.
Typical failure points include:
- Throttling under load: peak traffic exposes rate limits that weren't obvious in testing
- Schema drift: upstream fields change, optional attributes become mandatory, and integrations fail unnoticed
- Status inconsistency: one provider says pending, another says complete, and your UI invents certainty
- Observability gaps: no single trace shows what happened end to end
The vendor won't absorb your reputational damage
When a transfer fails, your customer doesn't ring the KYC supplier, FX provider, and payout processor one by one. They blame your brand.
That's why governance matters as much here as it does in low-code estates. The same discipline behind Power Platform governance applies to payment integrations. You need ownership, control boundaries, monitoring standards, and defined failure handling. Otherwise your internal teams spend their time mediating between suppliers while customers wait for answers.
APIs shorten coding time. They do not shorten accountability.
The practical answer isn't to avoid APIs. It's to treat them as volatile dependencies and architect for failure, not brochureware.
The Operational Risks That Blindside Technical Teams
Let's say your engineers did everything right. The app is stable. The controls are sensible. The integrations mostly hold. You can still fail in operations.
That happens more often than technical teams expect because money movement creates emotional, legal, and financial pressure in a way normal applications don't. Missing funds, delayed payouts, false fraud flags, and scam complaints all land on human teams first.
Fraud operations and customer support are part of the product
Your fraud model needs tuning, review, and exceptions handling. If it's too weak, bad transfers pass through. If it's too aggressive, good customers get blocked and abandon the service.
Support has the same problem. They don't need generic CRM notes. They need transaction history, decision evidence, payout dependencies, and clear action paths. If they can't see what happened, they'll escalate everything. That slows response times and increases complaint volume.
We often see teams underinvest in three capabilities:
- Manual review operations: queues, triage rules, and specialist workflows for suspicious transfers
- Dispute handling: evidence collection, timeline reconstruction, and customer communication templates
- Knowledge management: corridor-specific rules, payout exceptions, and recurring failure patterns
Auditability is not a reporting feature
An auditor, regulator, or lawyer won't accept "the logs are in different systems". They will ask for the complete record of the transaction lifecycle.
That means your operational model needs immutable event capture, consistent transaction identifiers, searchable case history, and retention policies that match your obligations. If your test strategy hasn't validated those paths, you're guessing. The same discipline described in thorough testing approaches for enterprise systems matters here. You need to test exception handling, not just successful transfers.
A practical operating model usually needs these artefacts:
| Operational need | What your team must be able to produce |
|---|---|
| Customer complaint | Full timeline, quoted amount, route taken, current status |
| Fraud investigation | Device and behaviour evidence, approval trail, intervention history |
| Reconciliation issue | Internal ledger entries, provider responses, settlement references |
| Regulatory review | Policy mapping, event history, decision logic, retained evidence |
Your application promises speed. Your operations team has to prove truth.
If that operating model isn't funded, the platform will accumulate risk without detection until the first serious incident exposes it.
The Real Choice Build vs Buy Is a False Dichotomy
The build versus buy debate wastes time because it asks the wrong question.
A full in-house build gives you control, but it also gives you full ownership of compliance logic, routing economics, fraud operations, and every ugly exception no vendor deck mentions. Buying a platform or stitching together providers sounds safer, but then you inherit opaque dependencies, limited control over change, and somebody else's outage calendar.
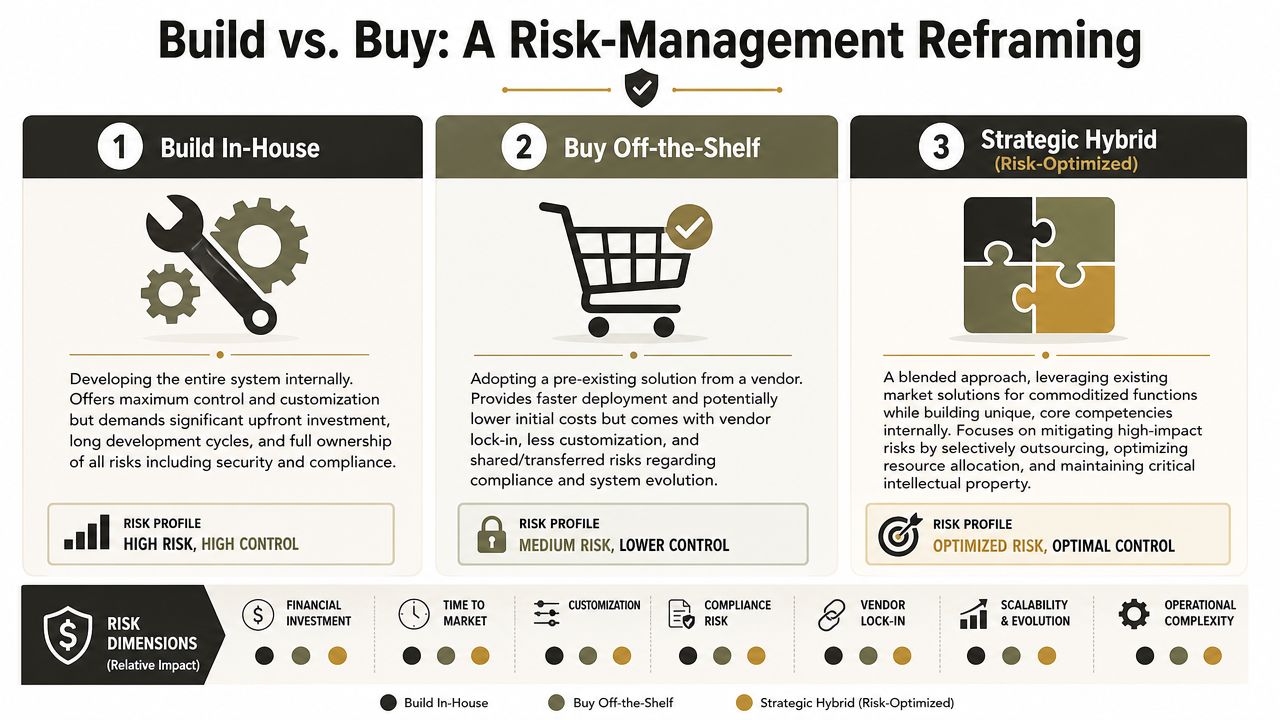
The decision that matters is simpler. Who owns risk with enough competence to control it?
A more honest decision framework
Use this lens instead:
- Build in-house if you already have serious engineering, compliance, fraud, and operations depth. Few teams do.
- Buy off the shelf if your use case is narrow and you can tolerate vendor constraints, limited differentiation, and dependency risk.
- Choose a strategic hybrid if you want control over critical flows but won't pretend commodity functions are strategic IP.
Many CTOs make the most expensive mistake. They try to save money by avoiding specialist oversight. That doesn't reduce cost. It defers cost until the first audit failure, fraud event, or dispute backlog.
The Ollo Verdict: don't ask whether to build or buy. Ask whether your current team can design, govern, and operate a money transfer application without creating hidden liability. If the answer is uncertain, you need specialist leadership before you need another sprint.
If your organisation is dealing with high-risk cloud, compliance, or platform modernisation work, Ollo helps IT leaders avoid the kind of architectural mistakes that become operational disasters later. When the stakes involve regulated data, audit trails, and business-critical systems, the cheapest path is rarely the safe one.



